KGQA_SHZ
简介
基于Neo4j的《水浒传》人物关系可视化及问答系统,该项目可以作为毕业设计,主要用涉及领域包括知识图谱、自然语言处理等知识。运用到的技术架构包括中文自然语言处理技术LTP模型、Python Flask框架、Neo4j图数据库。raw_data是人工合成的数据,spider中的数据是爬取的人物图片数据和人物基本信息数据。
一.项目背景
近年来网络文学蓬勃发展,文学作品的数量和题材层出不穷。一部文学作品的字数通常是超过百万的,这就使得用户仅仅通过自己阅读是很难准确地捕捉到作品中具体的人物关系。如果使用传统的搜索引擎对文学作品中的人物关系进行查询,得到的结果往往都是相对应的大量文字片段的网页链接,无法得到简洁准确的答案。由此,能够弥补上述缺陷的问答系统逐渐受到广泛关注,它不仅允许用户以自然语言的方式进行提问,还能够实现针对用户提问返回相应简洁准确答案句的功能,在一定程度上提高了用户的查询效率。此外,关于中文问答系统的研究还不够成熟,中文语法及语义的复杂性给问答系统研究带来了不小挑战,因此,针对中文的语句相似度研究、文本检索、知识推理等问答系统的应用前景广阔,且有很大发展空间。
二.项目介绍
本项目是对中文问答系统的探索,针对文学作品人物关系复杂,无法进行快速准确查询的问题,本项目提出基于水浒传的人物关系可视化及问答系统,并进行了实例验证,采用分词、句法分析等自然语言处理技术,研究了文学作品水浒传中人物关系,实现了根据用户输入的人物名称快速返回其人物关系的功能,项目功能包括三个主要部分:人物关系检索、人物关系全貌展示和人物关系问答。对于用户提交的问题,首先利用哈工大的语言技术处理平台LTP进行分词,提取关键词;其次,对于已经预处理的数据建立图数据库,然后用分词提取出来的关键字进行Neo4j图数据库的查询,匹配相关信息,利用Python Flask建立前端展示页面,建立知识图谱展示。目前,自然语言处理应用于各个领域,如教育、医疗、司法、金融等等。本项目立足经典著作《水浒传》,爬取水浒传人物数据,构建起一个包含7类实体的水浒传人物关系知识图谱,以及关于水浒传人物关系的问答系统。本项目主要包含以下内容:
- 基于neo4j的水浒传人物关系检索查询。
- 基于neo4j的水浒传人物关系全貌查询。
- 基于neo4j的水浒传人物关系问答系统。
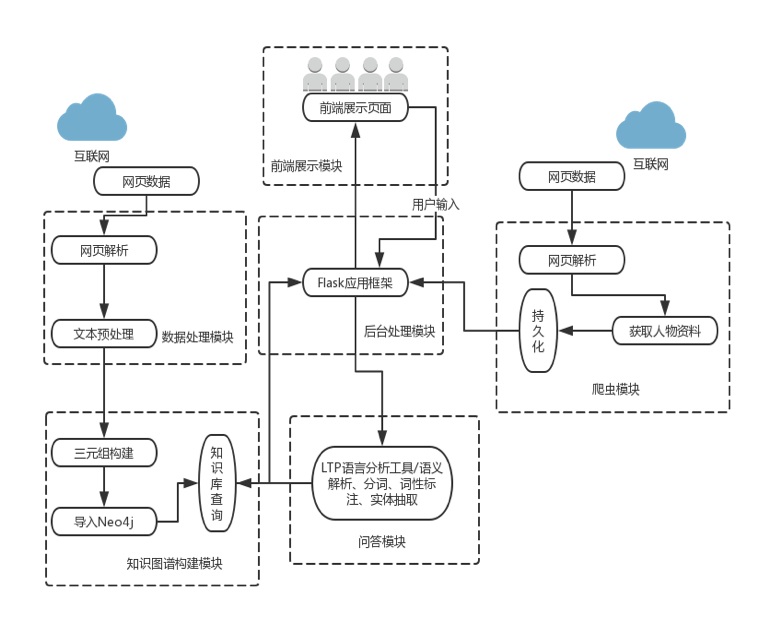
三.项目结构
本项目主要分为以下几个模块:
- spider模块爬取人物资料,包括人物图片images,人物基本信息(别名、性别、籍贯等)json,生成data.json文件。
- raw_data文件夹是存放数据处理后的三元组文件。
- neo_db模块创建知识图谱,建立图数据库以及进行知识图谱的查询。
- KGQA模块是问答系统模块,主要进行分词、词性标注、命名实体识别。
- templates模块是HTML页面模块,包括欢迎界面、搜索人物关系页面、人物关系全貌页面人物关系问答页面。
- static模块存放css和js,是页面样式和效果文件。
- app.py是整个系统的主入口。
四.总体功能设计
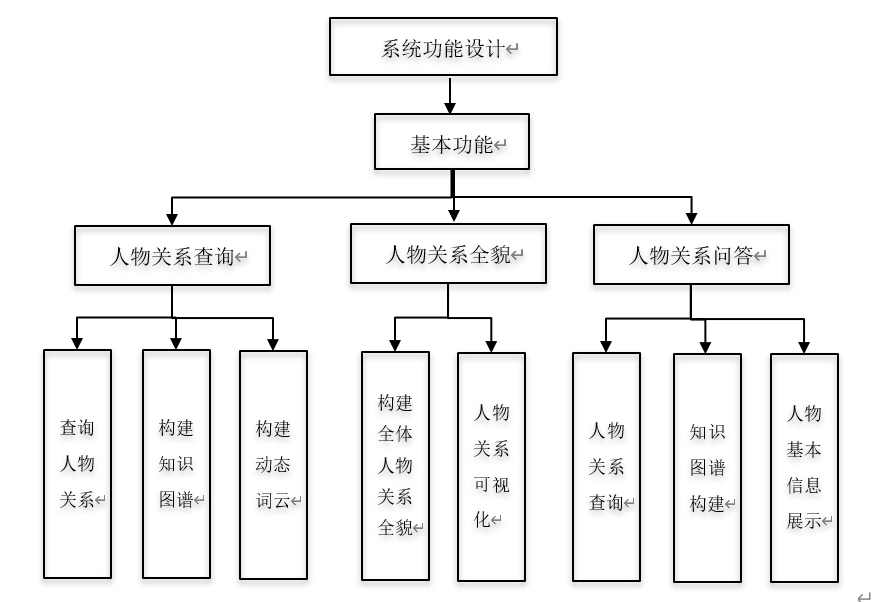
五.项目流程
六.成果展示
首页
 人物关系检索
人物关系检索
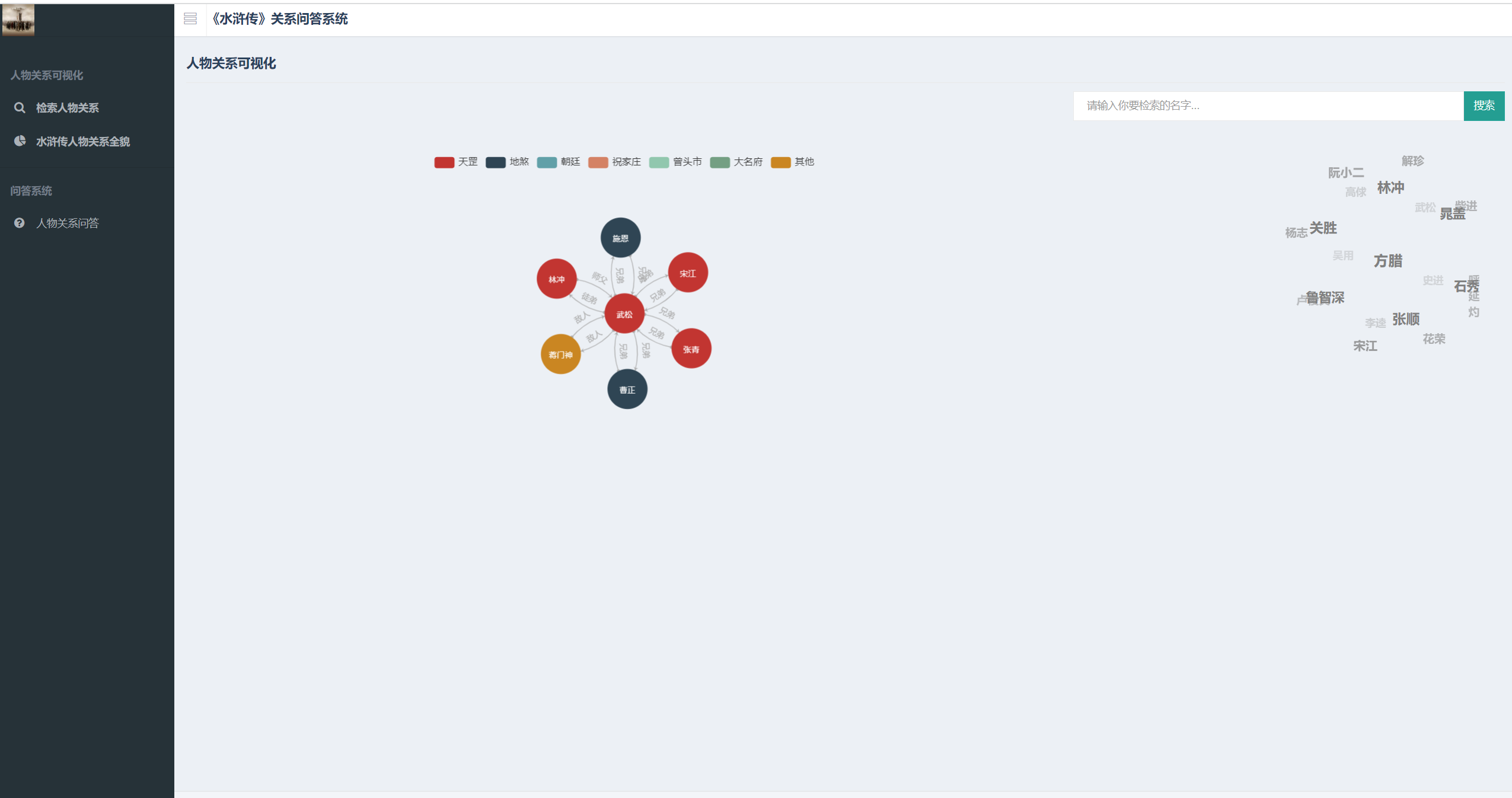 人物关系全貌
人物关系全貌
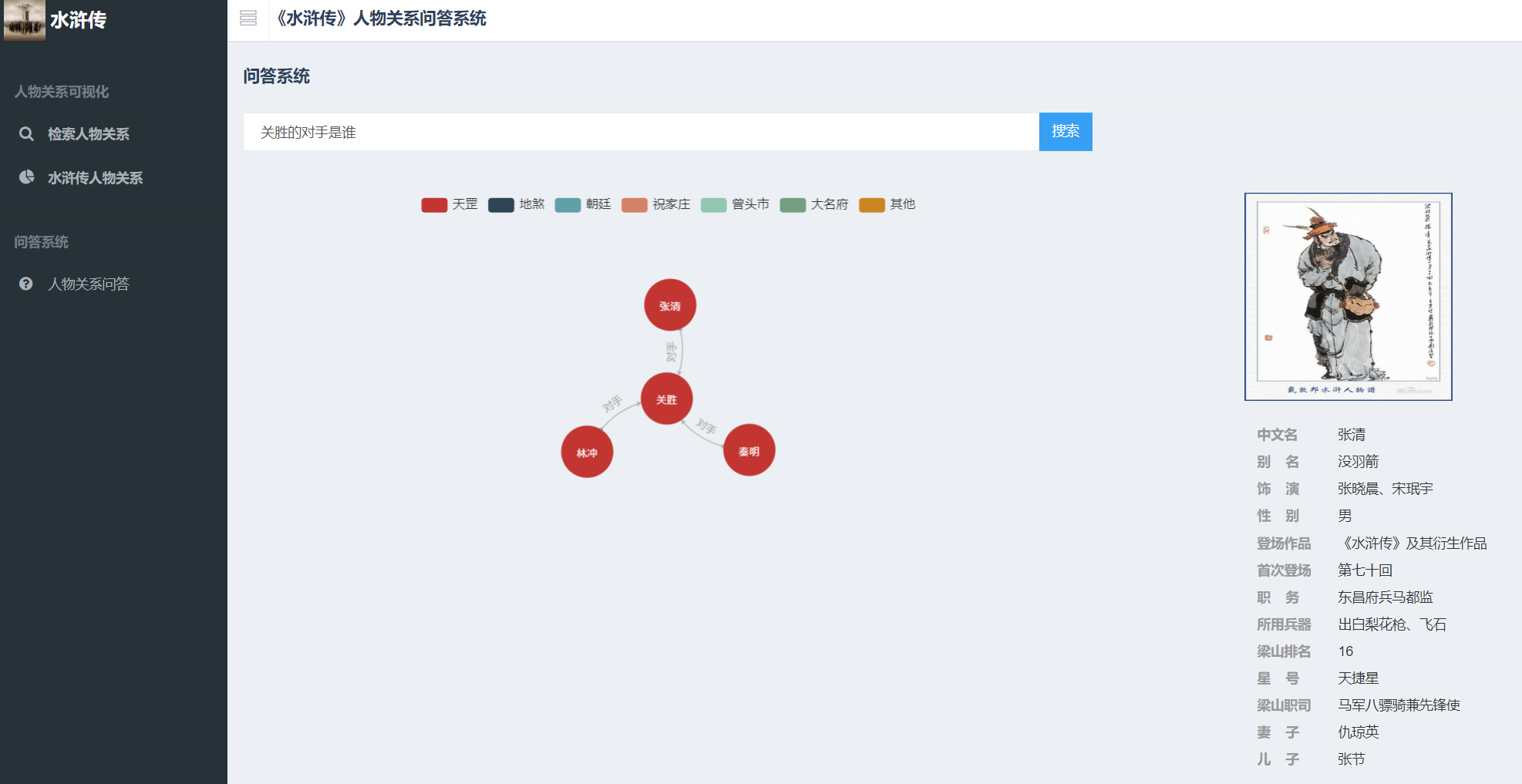
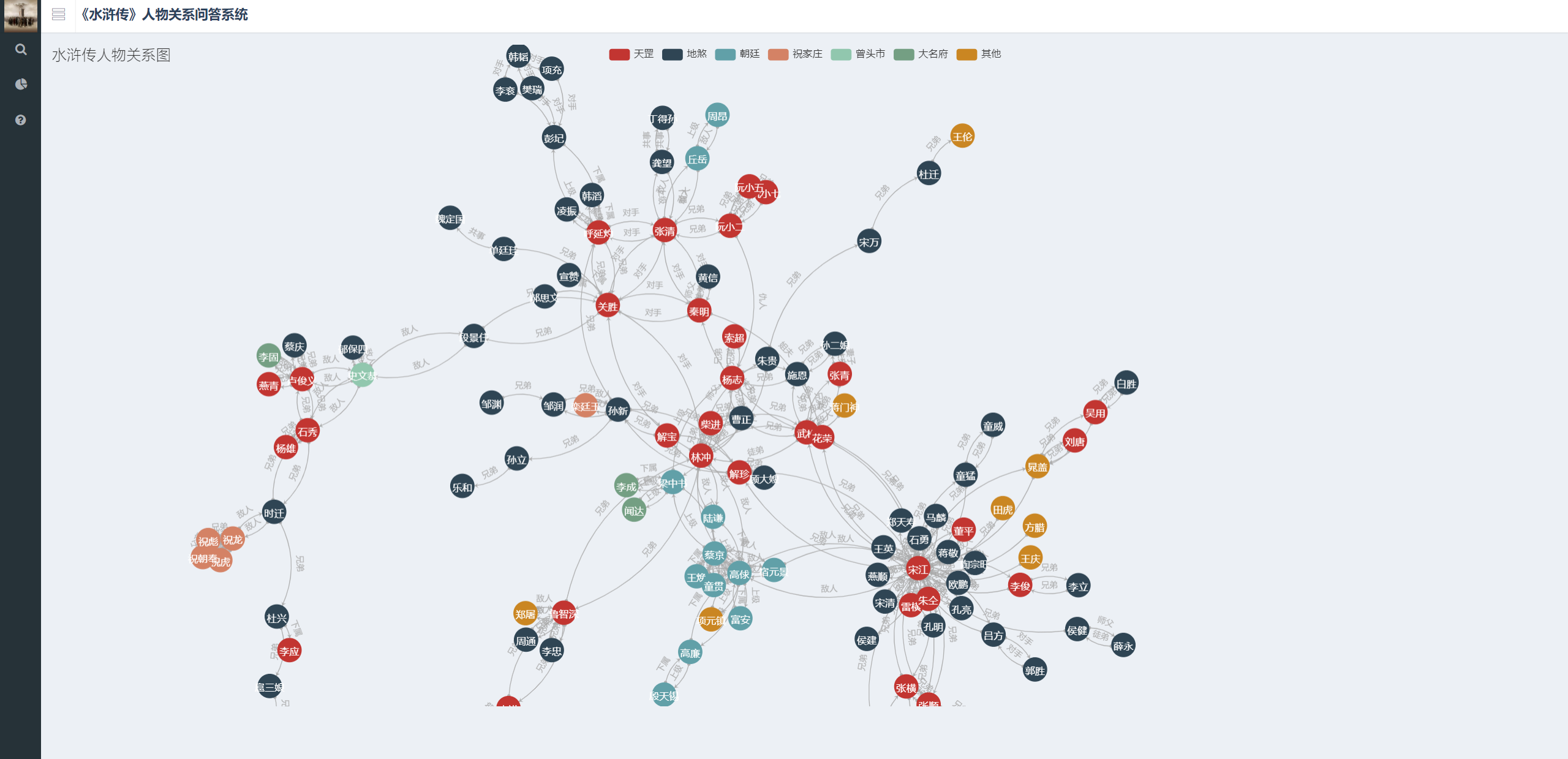 人物关系问答
人物关系问答
七.部署步骤
- 0.安装所需的库 执行pip install -r requirement.txt
- 1.先下载好neo4j图数据库,并配好环境。修改neo_db目录下的配置文件config.py,设置图数据库的账号和密码。在cmd中运行neo4j.bat console命令。
- 2.切换到neo_db目录下,执行python create_graph.py 建立知识图谱
- 3.下载好ltp_3.4.0 模型,LTP下载,提取码:cpvn。注意放到根目录下,如:D:\ltp_data_v3.4.0。ltp简介
- 4.在KGQA目录下,修改ltp.py里的ltp模型文件的存放目录
- 5.运行python app.py,浏览器打开localhost:5000即可查看
八.说明
文件介绍:
- app.py是整个系统的主入口
- templates文件夹是HTML的页面
|-index.html 首页界面
|-search.html 人物关系检索页面
|-all_relation.html 人物关系全貌页面
|-KGQA.html 人物关系问答页面
- static文件夹存放css和js,是页面的样式和效果的文件
- raw_data文件夹是存在数据处理后的三元组文件
- neo_db文件夹是知识图谱构建模块
|-config.py 配置参数
|-create_graph.py 创建知识图谱,图数据库的建立
|-query_graph.py 知识图谱的查询
- KGQA文件夹是问答系统模块
|-ltp.py 分词、词性标注、命名实体识别
- spider文件夹是爬虫模块
|- get_*.py 是之前爬取人物资料的代码,已经产生好images和json 可以不用再执行
|-show_profile.py 是调用人物资料和图谱展示在前端的代码。
运行环境介绍:
- windows10 系统、pycharm professional 2021.3.3、python3.6、neo4j-community-4.4.11、ltp_3.4.0
- python库的版本:Flask 1.0 、py2neo 2020.1.0、pyltp 0.2.1、bs4 0.0.0
- 关于neo4j的安装,可以参考Neo4j安装教程,提取码:g742,PS:本人用的JDK是jdk11
九.不足与改进
本项目的局限性与改进方法如下:
- relation.txt中存储的是人物关系数据,人物关系数据的大小影响着问答系统最终展示给用户图谱的大小,人物关系数据越多,生成的图谱就越复杂,人物关系越少,生成的实体关系就越少。其次,该数据文件是由人工合成的,数据量较少,该项目的一个可拓展的方向就是如何从网页爬取人物关系数据,并且生成一个三元组文件。
- 关于问答页面右侧的人物信息展示,是依照relation.txt的数据集中的第一列人名进行网络爬取,爬取对应人名的图片及简介,该做法会导致爬取的人物信息不是水浒传人物信息,导致结果不匹配,这是本项目的第二个局限性,如何筛选出水浒传人物图片与信息是该项目可改进的方向。
- 问答系统中,输入问句进行分词、句法分析会出现分词结果不准确,切分词错乱,导致无法在数据库中找到创建的图谱,也是本项目的一个局限性,改进方法是对输入的不同类型的句子利用多种切分方式进行分词。
十.参考资料
-
基于知识图谱的《红楼梦人物关系可视化及问答系统》,本项目是对该项目的改编。
-
中文开放知识图谱,这里可以获取知识图谱相关数据集。
If any question about the project or me , please feel free to contact me :zrh023@gmail.com
myblog: https://zrhcode.github.io/ 









